As Intigriti retweeted my last post I found out they had a CTF
running until the 16th of January 2018.
As I always like a challenge, and there was a Burp license to be won, I had a
quick look at it.
I’m a sore loser but I will nonetheless tell you how I went about it and got
stuck in the end.
There was only this tweet to get started with:
CHALLENGE: FIND THE FLAG🚩 & WIN🏆! There's a secret flag hidden in this tweet. Can you find it? 🕵️ Check the rules in the replies! 👇#HackWithIntigriti #BugBounty #CTF pic.twitter.com/0PFZNd692W
— intigriti (@intigriti) January 9, 2019
Nothing really interesting in the text itself so I went with the image.
Running strings on the file revealed some stuff that shouldn’t have been
there:
$ strings DweADlgXgAAehHh.jpg_large
JFIF
ICC_PROFILE
Z<!--
mntrRGB XYZ
acsp
lmao
nottheflag.pdfUT
4\ux
o{SW
vqE"L
s6f_
...
Somebody taunting us: lmao, and the name of a PDF file: nottheflag.pdf.
That PDF file was probably appended to the JPEG file. In that case, binwalk is
a nice tool to extract it. It’s originally made to extract resources from binary
firmwares.
$ binwalk -e DweADlgXgAAehHh.jpg_large
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 JPEG image data, JFIF standard 1.01
182 0xB6 Zip archive data, at least v2.0 to extract, compressed size: 11029, uncompressed size: 12129, name: nottheflag.pdf
65660 0x1007C End of Zip archive, footer length: 22
It confirms that another file is embedded in the image, but this is, in fact, a
ZIP file instead of a PDF. The PDF is probably in the ZIP though.
Everything got extracted to a _DweADlgXgAAehHh.jpg_large.extracted directory.
$ ls -l _DweADlgXgAAehHh.jpg_large.extracted/
total 116
-rw-rw-r--. 1 rm rm 105240 Jan 16 06:44 B6.zip
-rw-rw-r--. 1 rm rm 12129 Jan 8 16:53 nottheflag.pdf
So there it is: the nottheflag.pdf file.
Opening it in a PDF reader reveals what looks like a Base64 encoded string:
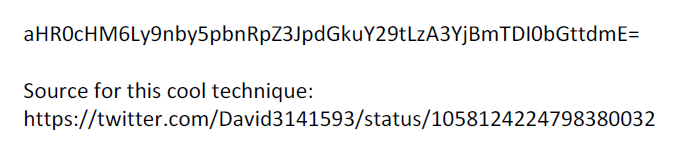
After decoding, we have a URL:
$ echo aHR0cHM6Ly9nby5pbnRpZ3JpdGkuY29tLzA3YjBmTDI0bGttdmE= | base64 -d
https://go.intigriti.com/07b0fL24lkmva
From that URL we get another ZIP file:
$ wget https://go.intigriti.com/07b0fL24lkmva
--2019-01-16 07:05:05-- https://go.intigriti.com/07b0fL24lkmva
Resolving go.intigriti.com (go.intigriti.com)... 52.72.49.79
Connecting to go.intigriti.com (go.intigriti.com)|52.72.49.79|:443... connected.
HTTP request sent, awaiting response... 301 Moved Permanently
Location: https://storage.googleapis.com/intigriti/community/data.zip [following]
--2019-01-16 07:05:05-- https://storage.googleapis.com/intigriti/community/data.zip
Resolving storage.googleapis.com (storage.googleapis.com)... 216.58.206.80, 2a00:1450:4009:815::2010
Connecting to storage.googleapis.com (storage.googleapis.com)|216.58.206.80|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 162523 (159K) [application/zip]
Saving to: ‘07b0fL24lkmva’
07b0fL24lkmva 100%[============================================================================>] 158.71K --.-KB/s in 0.002s
2019-01-16 07:05:05 (95.5 MB/s) - ‘07b0fL24lkmva’ saved [162523/162523]
$ file 07b0fL24lkmva
07b0fL24lkmva: Zip archive data, at least v1.0 to extract
But that time the ZIP file is encrypted:
$ unzip 07b0fL24lkmva
Archive: 07b0fL24lkmva
[07b0fL24lkmva] data/1_177.jpg password:
password incorrect--reenter:
$
From there I need to get back to another thing I found out on that original tweet: there was a hidden link in it. As you can see when looking at the source:
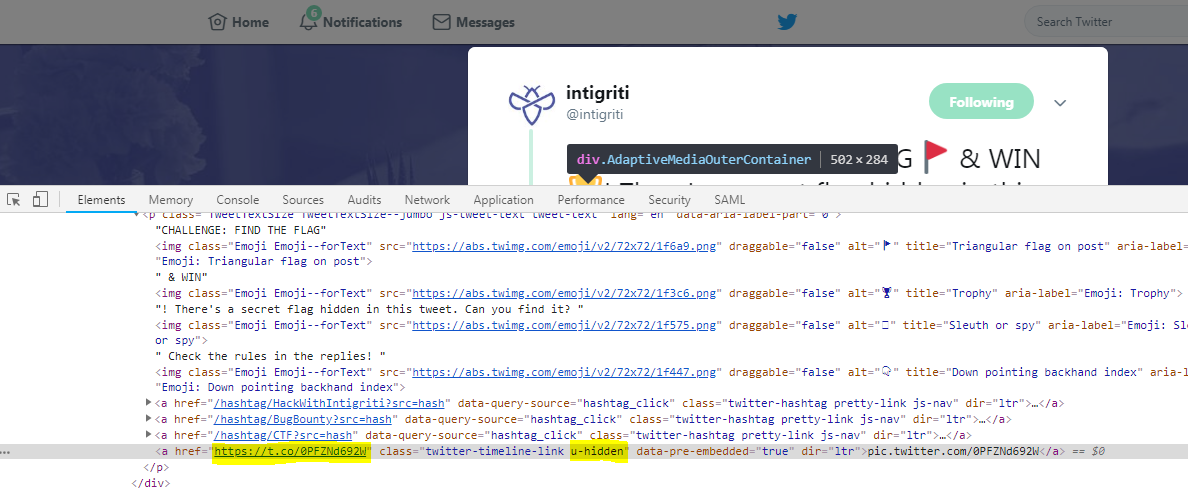
It links to another Twitter profile created specifically for the CTF:
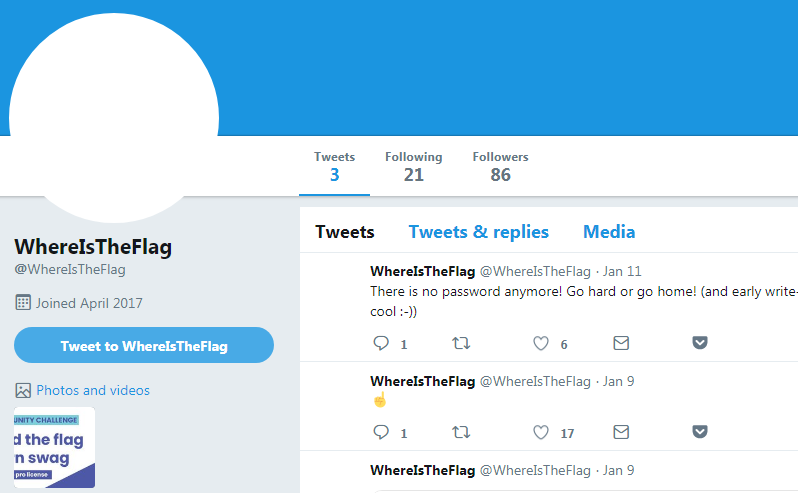
Not much on it, apart from the profile pic. I looked at it with strings like
the first one to check for weird strings in it, with an hex editor to look for
patterns that I would recognize and with Gimp in case there was something hidden
in image itself. And I found nothing…
One thing was missing on that profile though and it was the banner pic. From that
and stuff I read on Twitter, I can only guess that it was were the password to
the encrypted ZIP file was hidden.
Anyway I was back to my ZIP file trying to extract data from it without the
password. I did try to crack it, although Intigriti gave an hint that it wasn’t
necessary, or even realistically possible.
When extracting it without password, some files were created but they were empty.
I looked at the content of the ZIP:
$ unzip -l 07b0fL24lkmva
Archive: 07b0fL24lkmva
Length Date Time Name
--------- ---------- ----- ----
0 01-03-2019 12:53 data/
314 01-03-2019 10:56 data/1_177.jpg
314 01-03-2019 10:56 data/1_163.jpg
314 01-03-2019 10:56 data/1_188.jpg
314 01-03-2019 10:56 data/1_349.jpg
318 01-03-2019 10:55 data/1_70.jpg
...
314 01-03-2019 10:56 data/1_146.jpg
314 01-03-2019 10:56 data/1_152.jpg
--------- -------
138677 442 files
So it contained 1 directory and 441 small JPEG files. All files were numbered, it
might have been important.
441 files made me think of a matrix of 21 by 21 which also is the size of the
smallest QR code format. All files had a size of either 314 or 318. I was
probably looking at all black or all white images that, when put in the right
order, formed a QR code.
All I needed to know was:
- the color of each image
- the order in which they should be arranged
Although looking at the file size was a good idea at first, the distribution made me think that it wasn’t the good way to go about it. There was:
- 390 files with size 314
- 50 files with size 318
- 1 file with size 317
I didn’t lookup stats on QR codes but from experience, the distribution should have been more balanced between black and white.
I thought that maybe if the files where encrypted with the same password, all
the black files would have the same encrypted data. So I read the specs of the
ZIP format in order to be able to confirm that hypothesis. And I came across
another interesting piece of data contained in the ZIP file: each compressed file
has a corresponding CRC included.
When I looked at them, most were the same:
$ unzip -lv 07b0fL24lkmva | tr -s " " | cut -d " " -f 8 | sort | uniq -c
3
1 ----
1 00000000
36 22eb0bb8
14 5b808910
1 81f9bf5a
206 96ee0cb5
184 c79dd362
1 CRC-32
Even though I didn’t have only 2 CRCs, the distribution looked way more realistic.
Now I only had to find out how to recreate the QR code from that.
I first went using the black and white files sequencially based on the number in
the file name. So the first line of the QR code would be files 1_01.jpg to
1_21.jpg, and on until file 1_441.jpg.
Here is the result:

You can see that it doesn’t really look like what I was looking for. I tried to reverse it but it’s not any better:
As I already had the JPEG Wikipedia page open from earlier, I remembered I had
seen something that could help me: the way JPEG blocks are reordered
I wrote a small script to do that and got the following result:
{kind=link}

And in reverse:

Not better in any way…
And that’s where I got stuck the morning the CTF was ending as I was at work the whole
day.
I just had to wait for the results and the eventual write-ups in the evening to see
where I went wrong.
As I could predict, it was staring me in the face the whole time… I had everything
I needed. There was just a small mistake in my script. I had it fixed in about 5 minutes.
Anyway it was good fun! Thanks Intigriti for putting this up 👍
I’m eagerly waiting for the next one!